最近读了一些Transformer的文章,记录一下.
由于刚开始读论文,而且不知道自己要从论文中找什么信息,所以完全看不懂,下文的理解非常粗俗.
我会回过头再看好几遍文章的…
1706.03762 经典永流传
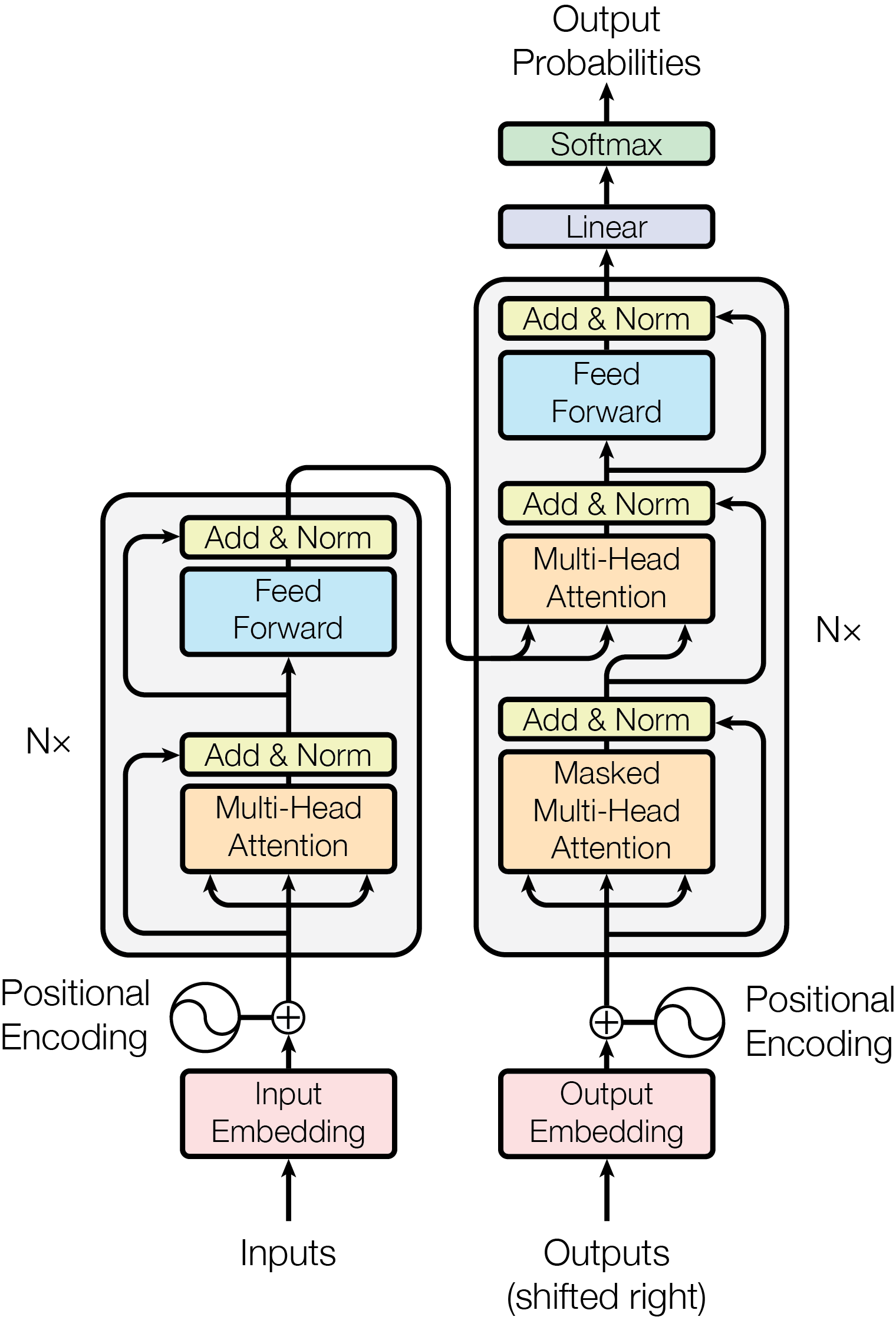
这篇文章提出了一个Transformer架构,基于注意力机制,丢掉了循环,卷积,递归网络.
然后文章说多头注意力机制比缩放点积注意力机制要好一些,因为多头意味着能注意到多个关键点.
- 卷积核:一个能突出特定模式的矩阵.
- label smoothing:训练时防止模型太过极端,不把标签设置太绝对的手段.
- tensor:张量,包含向量,可以理解为程序中传递的各种参数矩阵或数组.
- tensor2tensor是一个深度学习库,现生态已被tensorflow替代.
- 因为Attn不能感知词序,所以论文添加了位置编码,把sin加进去(可以保证线性变换),让模型能识别位置关系(后世似乎用RoPE的比较多),位置: $x=e+PE$ ,e是embedding,PE是位置编码
传统Attention影响太过深远以至于后世都在Attn上雕花,几乎没有新架构,有也是把编码器删了.
flash attention
cross attention
page attention
rope
fused attention